
本页介绍了基于任务的构建系统、其工作原理以及基于任务的系统可能出现的一些复杂情况。在 Shell 脚本之后,基于任务的构建系统是构建的下一个逻辑演变。
了解基于任务的构建系统
在基于任务的构建系统中,基本工作单元是任务。每个任务都是一个脚本,可以执行任何类型的逻辑,并且任务会将其他任务指定为必须在它们之前运行的依赖项。如今使用的大多数主要构建系统(例如 Ant、Maven、Gradle、Grunt 和 Rake)都是基于任务的。大多数现代构建系统都要求工程师创建构建文件来描述如何执行构建,而不是使用 Shell 脚本。
请看 Ant 手册中的以下示例:
<project name="MyProject" default="dist" basedir=".">
<description>
simple example build file
</description>
<!-- set global properties for this build -->
<property name="src" location="src"/>
<property name="build" location="build"/>
<property name="dist" location="dist"/>
<target name="init">
<!-- Create the time stamp -->
<tstamp/>
<!-- Create the build directory structure used by compile -->
<mkdir dir="${build}"/>
</target>
<target name="compile" depends="init"
description="compile the source">
<!-- Compile the Java code from ${src} into ${build} -->
<javac srcdir="${src}" destdir="${build}"/>
</target>
<target name="dist" depends="compile"
description="generate the distribution">
<!-- Create the distribution directory -->
<mkdir dir="${dist}/lib"/>
<!-- Put everything in ${build} into the MyProject-${DSTAMP}.jar file -->
<jar jarfile="${dist}/lib/MyProject-${DSTAMP}.jar" basedir="${build}"/>
</target>
<target name="clean"
description="clean up">
<!-- Delete the ${build} and ${dist} directory trees -->
<delete dir="${build}"/>
<delete dir="${dist}"/>
</target>
</project>
构建文件以 XML 编写,并定义了一些关于构建的简单元数据
以及任务列表(XML 中的 <target> 标记)。(Ant 使用字词
目标来表示任务,并使用字词任务来指代
命令。)每个任务都会执行 Ant 定义的一系列可能命令,这些命令包括创建和删除目录、运行 javac 以及创建 JAR 文件。用户提供的插件可以扩展此命令集,以涵盖任何类型的逻辑。每个任务还可以通过 depends 属性定义其依赖的任务。这些依赖项形成一个非循环图,如图 1 所示。
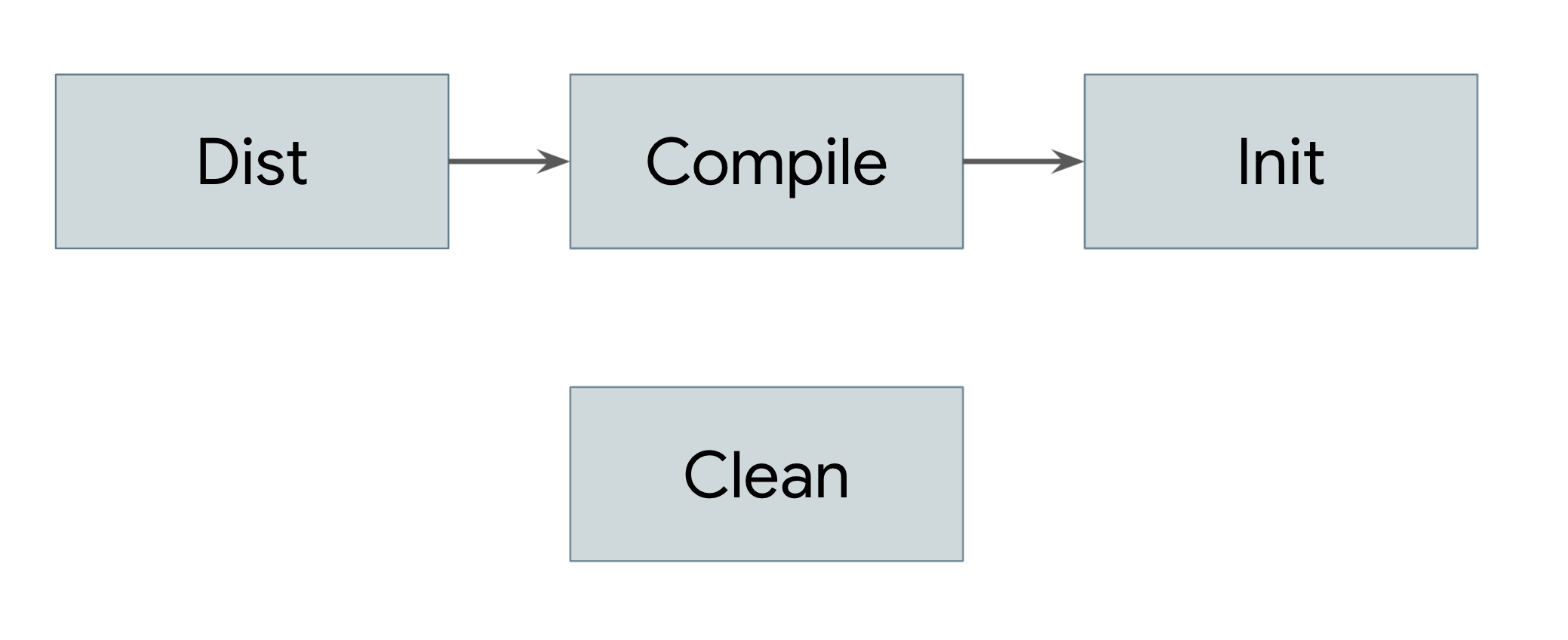
图 1. 显示依赖项的非循环图
用户通过向 Ant 的命令行工具提供任务来执行构建。例如,当用户输入 ant dist 时,Ant 会执行以下步骤:
- 加载当前目录中名为
build.xml的文件,并对其进行解析以创建图 1 中所示的图结构。 - 查找在命令行中提供的名为
dist的任务,并发现它依赖于名为compile的任务。 - 查找名为
compile的任务,并发现它依赖于名为init的任务。 - 查找名为
init的任务,并发现它没有任何依赖项。 - 执行
init任务中定义的命令。 - 执行
compile任务中定义的命令,前提是该任务的所有依赖项都已运行。 - 执行
dist任务中定义的命令,前提是该任务的所有依赖项都已运行。
最后,Ant 在运行 dist 任务时执行的代码等效于以下 Shell 脚本:
./createTimestamp.shmkdir build/javac src/* -d build/mkdir -p dist/lib/jar cf dist/lib/MyProject-$(date --iso-8601).jar build/*
如果去掉语法,构建文件和构建脚本实际上并没有太大的区别。但我们已经从中获益良多。我们可以在其他目录中创建新的构建文件,并将它们链接在一起。我们可以轻松地以任意复杂的方式添加依赖于现有任务的新任务。我们只需要将单个任务的名称传递给 ant 命令行工具,它就会确定需要运行的所有内容。
Ant 是一款旧软件,最初于 2000 年发布。在随后的几年中,Maven 和 Gradle 等其他工具对 Ant 进行了改进,并通过添加自动管理外部依赖项和更简洁的无 XML 语法等功能,基本上取代了 Ant。但这些较新系统的本质保持不变:它们允许工程师以有原则且模块化的方式将构建脚本编写为任务,并提供用于执行这些任务和管理任务之间依赖项的工具。
基于任务的构建系统的缺点
由于这些工具基本上允许工程师将任何脚本定义为任务,因此它们非常强大,让您几乎可以利用它们完成任何您能想到的事情。但这种强大功能也有缺点,并且随着构建脚本变得越来越复杂,基于任务的构建系统可能会变得难以使用。此类系统的问题在于,它们实际上最终会向工程师提供过多的权限,而向系统提供的权限不足。 由于系统不知道脚本在做什么,因此性能会受到影响,因为它在安排和执行构建步骤时必须非常保守。并且系统无法确认每个脚本都在执行其应执行的操作,因此脚本往往会变得越来越复杂,最终成为需要调试的另一项内容。
难以并行执行构建步骤
现代开发工作站非常强大,具有多个内核,能够并行执行多个构建步骤。但基于任务的系统通常无法并行执行任务,即使看起来应该能够并行执行也是如此。假设任务 A 依赖于任务 B 和 C。由于任务 B 和 C 彼此之间没有任何依赖关系,因此同时运行它们是否安全,以便系统可以更快地执行任务 A?如果它们不触及任何相同的资源,则可能是安全的。但可能并非如此,也许两者都使用同一个文件来跟踪其状态,并且同时运行它们会导致冲突。系统通常无法知道这一点,因此要么必须冒着这些冲突的风险(导致罕见但难以调试的构建问题),要么必须将整个构建限制为在单个进程中的单个线程上运行。 这可能会极大地浪费强大的开发者机器,并且完全排除了将构建分布到多台机器上的可能性。
难以执行增量构建
一个好的构建系统允许工程师执行可靠的增量构建,这样一个小小的更改就不需要从头开始重建整个代码库。如果构建系统速度较慢且由于上述原因无法并行执行构建步骤,这一点尤其重要。但不幸的是,基于任务的构建系统在这方面也存在问题。由于任务可以执行任何操作,因此通常无法检查它们是否已完成。许多任务只是获取一组源文件并运行编译器来创建一组二进制文件;因此,如果底层源文件没有更改,则无需重新运行它们。但如果没有其他信息,系统就无法确定这一点,也许任务会下载一个可能已更改的文件,或者它可能会写入一个在每次运行时都可能不同的时间戳。为了保证正确性,系统通常必须在每次构建期间重新运行每个任务。一些构建系统尝试通过让工程师指定需要重新运行任务的条件来启用增量构建。有时这是可行的,但通常这是一个比看起来要棘手得多的问题。例如,在 C++ 等允许其他文件直接包含文件的语言中,如果不解析输入源,就无法确定必须监视更改的整个文件集。工程师通常最终会采取捷径,而这些捷径可能会导致罕见且令人沮丧的问题,即即使不应该重用任务结果,也会重用任务结果。如果这种情况经常发生,工程师就会养成在每次构建之前运行清理以获取全新状态的习惯,这完全违背了最初进行增量构建的目的。确定何时需要重新运行任务非常微妙,这是一项由机器而非人类来处理的工作。
难以维护和调试脚本
最后,基于任务的构建系统强加的构建脚本通常难以使用。虽然构建脚本通常较少受到审查,但它们与正在构建的系统一样都是代码,并且很容易隐藏 bug。 以下是一些在使用基于任务的构建系统时非常常见的 bug 示例:
- 任务 A 依赖于任务 B 来生成特定文件作为输出。任务 B 的所有者没有意识到其他任务依赖于它,因此他们更改了任务 B 以在不同的位置生成输出。在有人尝试运行任务 A 并发现它失败之前,无法检测到这一点。
- 任务 A 依赖于任务 B,而任务 B 依赖于任务 C,任务 C 生成任务 A 所需的特定文件作为输出。任务 B 的所有者决定不再需要依赖于任务 C,这会导致任务 A 失败,即使任务 B 根本不关心任务 C!
- 新任务的开发者意外地对运行该任务的机器做出假设,例如工具的位置或特定环境变量的值。该任务在他们的机器上运行正常,但每当其他开发者尝试运行该任务时,该任务都会失败。
- 任务包含一个非确定性组件,例如从互联网下载文件或向构建添加时间戳。现在,人们每次运行构建时都可能会得到不同的结果,这意味着工程师无法始终重现和修复彼此的失败或在自动化构建系统上发生的失败。
- 具有多个依赖项的任务可能会创建竞态条件。如果任务 A 同时依赖于任务 B 和任务 C,并且任务 B 和 C 都修改同一个文件,则任务 A 会得到不同的结果,具体取决于任务 B 和 C 中哪个先完成。
在本文介绍的基于任务的框架内,没有通用的方法来解决这些性能、正确性或可维护性问题。只要工程师可以编写在构建期间运行的任意代码,系统就无法获得足够的信息来始终能够快速且正确地运行构建。为了解决这个问题,我们需要从工程师手中夺回一些权力,并将其交还给系统,并重新构思系统的角色,不是运行任务,而是生成工件。
这种方法催生了基于工件的构建系统,例如 Blaze 和 Bazel。