
Quando você tem uma base de código grande, as cadeias de dependências podem ficar muito profundas. Mesmo binários simples podem depender de dezenas de milhares de destinos de build. Nessa escala, é simplesmente impossível concluir um build em um período razoável em uma única máquina: nenhum sistema de build pode contornar as leis fundamentais da física impostas ao hardware de uma máquina. A única maneira de fazer isso funcionar é com um sistema de build que ofereça suporte a builds distribuídos em que as unidades de trabalho realizadas pelo sistema sejam distribuídas por um número arbitrário e escalonável de máquinas. Supondo que tenhamos dividido o trabalho do sistema em unidades pequenas o suficiente (mais sobre isso adiante), isso nos permitiria concluir qualquer build de qualquer tamanho com a rapidez que estamos dispostos a pagar. Essa escalonabilidade é o objetivo que buscamos ao definir um sistema de build baseado em artefatos.
Armazenamento em cache remoto
O tipo mais simples de build distribuído é aquele que usa apenas o armazenamento em cache remoto, mostrado na Figura 1.
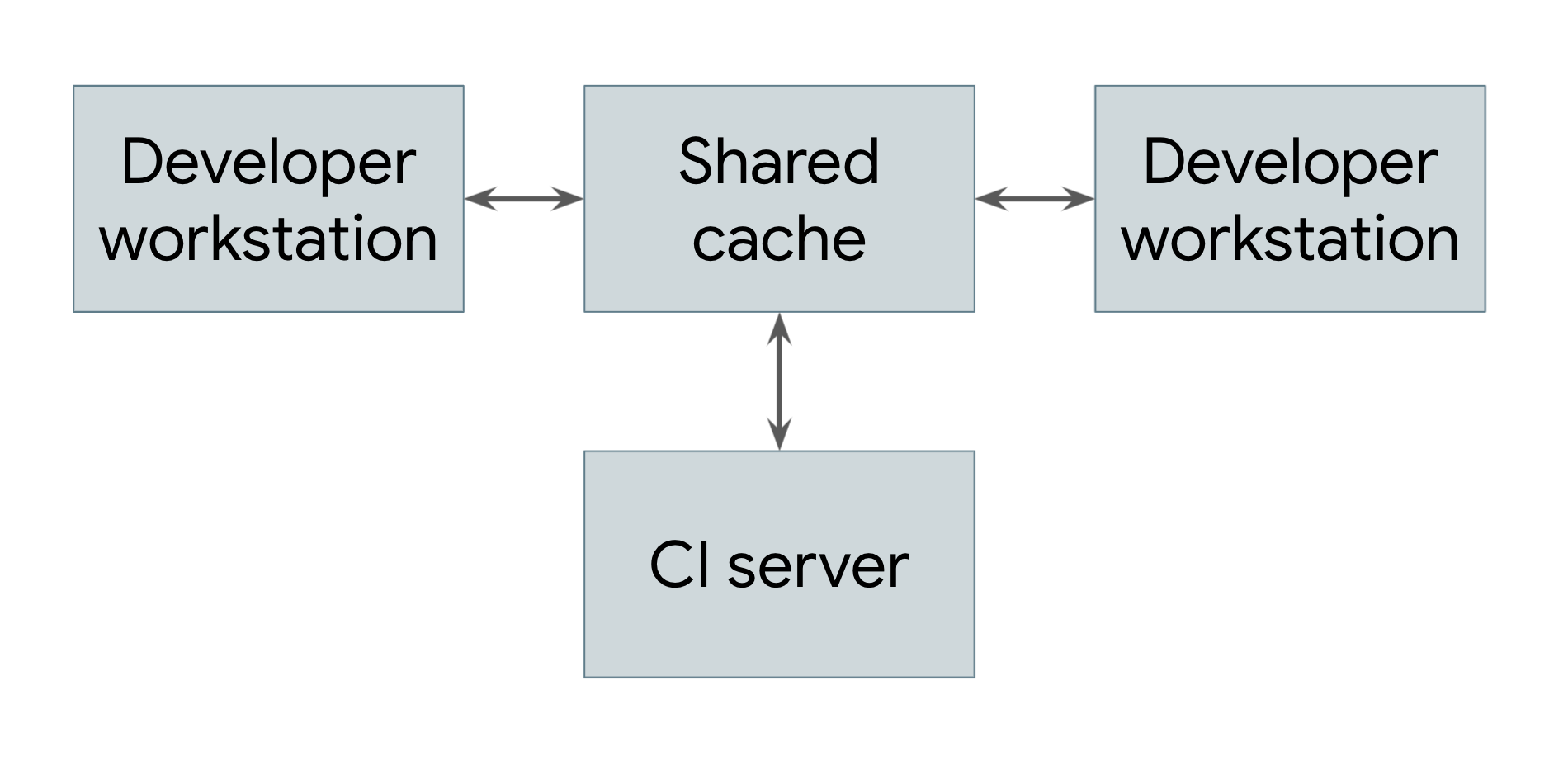
Figura 1. Um build distribuído mostrando o armazenamento em cache remoto
Todos os sistemas que realizam builds, incluindo estações de trabalho de desenvolvedores e sistemas de integração contínua, compartilham uma referência a um serviço de cache remoto comum. Esse serviço pode ser um sistema de armazenamento temporário rápido e local, como o Redis, ou um serviço de nuvem, como o Google Cloud Storage. Sempre que um usuário precisa criar um artefato, seja diretamente ou como uma dependência, o sistema primeiro verifica o cache remoto para saber se esse artefato já existe. Se for o caso, ele pode fazer o download do artefato em vez de criá-lo. Caso contrário, o sistema cria o artefato e faz o upload do resultado para o cache. Isso significa que as dependências de baixo nível que não mudam com muita frequência podem ser criadas uma vez e compartilhadas entre os usuários, em vez de serem recriadas por cada usuário. No Google, muitos artefatos são veiculados de um cache em vez de serem criados do zero, reduzindo muito o custo de execução do nosso sistema de build.
Para que um sistema de armazenamento em cache remoto funcione, o sistema de build precisa garantir que os builds sejam totalmente reproduzíveis. Ou seja, para qualquer destino de build, é preciso determinar o conjunto de entradas para esse destino, de modo que o mesmo conjunto de entradas produza exatamente a mesma saída em qualquer máquina. Essa é a única maneira de garantir que os resultados do download de um artefato sejam os mesmos da criação dele. Isso exige que cada artefato no cache seja chaveado no destino e em um hash das entradas. Dessa forma, engenheiros diferentes podem fazer modificações diferentes no mesmo destino ao mesmo tempo, e o cache remoto armazena todos os artefatos resultantes e os veicula adequadamente sem conflito.
É claro que, para que haja algum benefício de um cache remoto, o download de um artefato precisa ser mais rápido do que a criação dele. Isso nem sempre acontece, principalmente se o servidor de cache estiver longe da máquina que está fazendo o build. A rede e o sistema de build do Google são ajustados com cuidado para compartilhar rapidamente os resultados do build.
Execução remota
O armazenamento em cache remoto não é um build distribuído verdadeiro. Se o cache for perdido ou se você fizer uma mudança de baixo nível que exija a recriação de tudo, ainda será necessário realizar todo o build localmente na sua máquina. O objetivo real é oferecer suporte à execução remota, em que o trabalho real de fazer o build pode ser distribuído por qualquer número de workers. A Figura 2 mostra um sistema de execução remota.
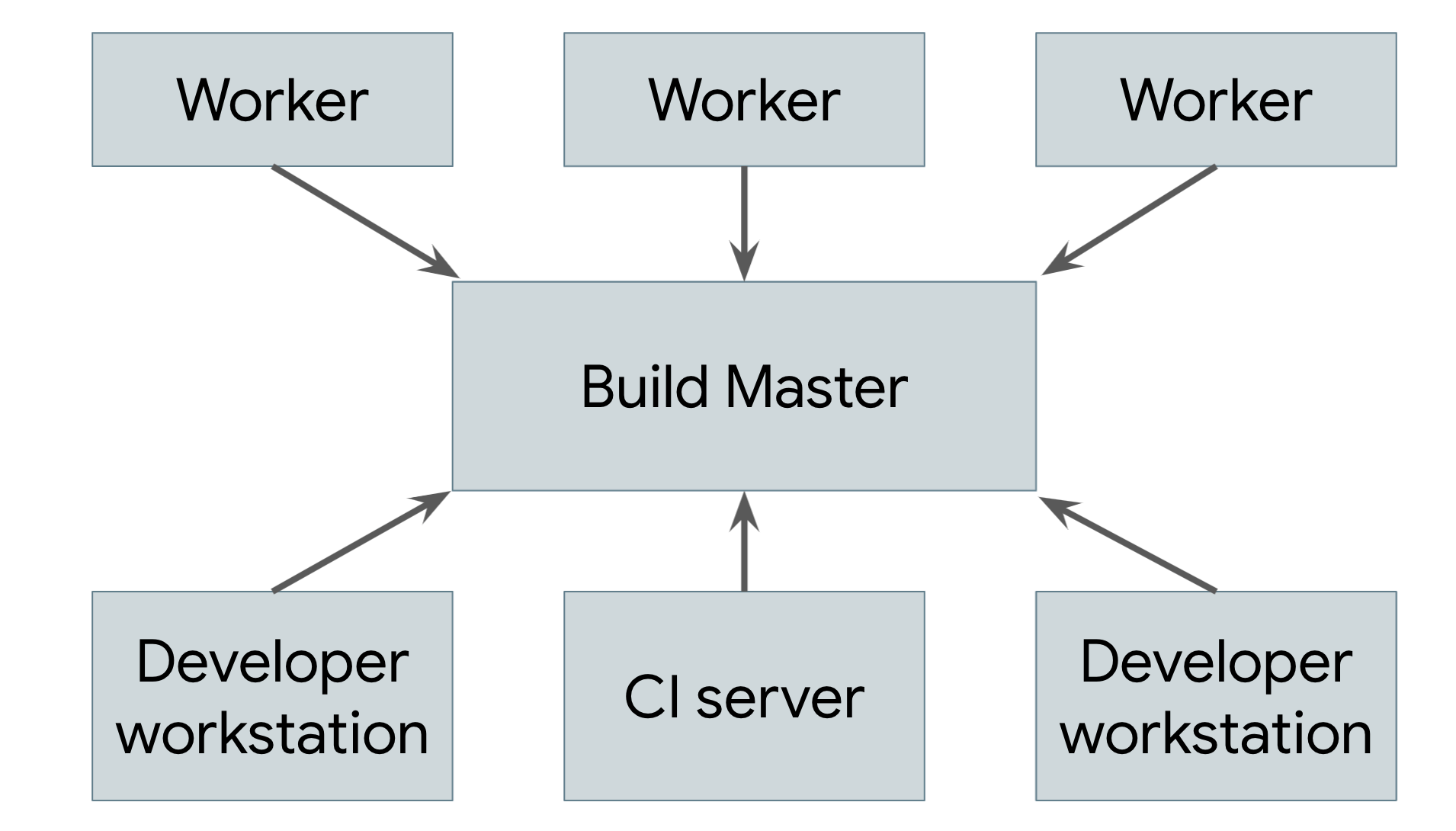
Figura 2. Um sistema de execução remota
A ferramenta de build em execução na máquina de cada usuário (em que os usuários são engenheiros humanos ou sistemas de build automatizados) envia solicitações a um mestre de build central. O mestre de build divide as solicitações em ações de componentes e agenda a execução dessas ações em um pool escalonável de workers. Cada worker executa as ações solicitadas com as entradas especificadas pelo usuário e grava os artefatos resultantes. Esses artefatos são compartilhados entre as outras máquinas que executam ações que os exigem até que a saída final possa ser produzida e enviada ao usuário.
A parte mais difícil da implementação de um sistema desse tipo é gerenciar a comunicação entre os workers, o mestre e a máquina local do usuário. Os workers podem depender de artefatos intermediários produzidos por outros workers, e a saída final precisa ser enviada de volta à máquina local do usuário. Para fazer isso, podemos criar um cache distribuído descrito anteriormente, fazendo com que cada worker grave os resultados e leia as dependências do cache. O mestre impede que os workers continuem até que tudo de que dependem seja concluído. Nesse caso, eles poderão ler as entradas do cache. O produto final também é armazenado em cache, permitindo que a máquina local faça o download. Também precisamos de um meio separado de exportar as mudanças locais na árvore de origem do usuário para que os workers possam aplicar essas mudanças antes de criar.
Para que isso funcione, todas as partes dos sistemas de build baseados em artefatos descritos anteriormente precisam se unir. Os ambientes de build precisam ser totalmente autodescritivos para que possamos ativar workers sem intervenção humana. Os processos de build precisam ser totalmente independentes, porque cada etapa pode ser executada em uma máquina diferente. As saídas precisam ser completamente determinísticas para que cada worker possa confiar nos resultados recebidos de outros workers. Essas garantias são extremamente difíceis de serem fornecidas por um sistema baseado em tarefas, o que torna quase impossível criar um sistema de execução remota confiável.
Builds distribuídos no Google
Desde 2008, o Google usa um sistema de build distribuído que emprega armazenamento em cache remoto e execução remota, ilustrado na Figura 3.
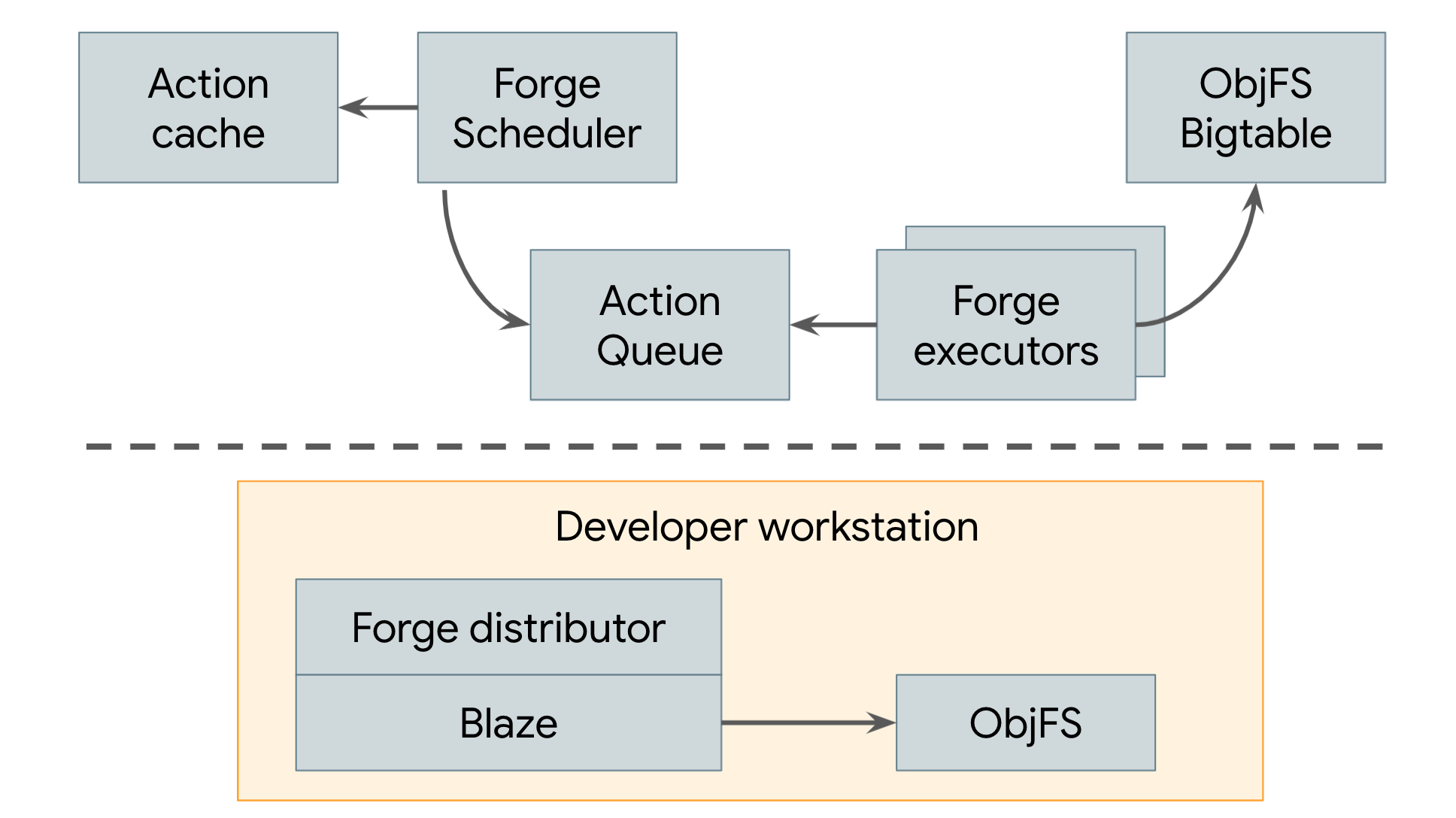
Figura 3. Sistema de build distribuído do Google
O cache remoto do Google é chamado de ObjFS. Ele consiste em um back-end que armazena saídas de build em Bigtables distribuídas por toda a nossa frota de máquinas de produção e um daemon FUSE de front-end chamado objfsd que é executado na máquina de cada desenvolvedor. O daemon FUSE permite que os engenheiros naveguem pelas saídas de build como se fossem arquivos normais armazenados na estação de trabalho, mas com o conteúdo do arquivo baixado sob demanda apenas para os poucos arquivos solicitados diretamente pelo usuário. A veiculação de conteúdo de arquivos sob demanda reduz muito o uso de rede e disco, e o sistema é capaz de criar duas vezes mais rápido em comparação com quando armazenamos toda a saída de build no disco local do desenvolvedor.
O sistema de execução remota do Google é chamado de Forge. Um cliente do Forge no Blaze (o equivalente interno do Bazel) chamado Distributor envia solicitações para cada ação a um job em execução nos nossos data centers chamado Scheduler. O Scheduler mantém um cache de resultados de ações, permitindo que ele retorne uma resposta imediatamente se a ação já tiver sido criada por qualquer outro usuário do sistema. Caso contrário, ele coloca a ação em uma fila. Um grande pool de jobs do Executor lê continuamente ações dessa fila, as executa e armazena os resultados diretamente nas Bigtables do ObjFS. Esses resultados ficam disponíveis para os executores de ações futuras ou para serem baixados pelo usuário final pelo objfsd.
O resultado final é um sistema que é escalonado para oferecer suporte eficiente a todos os builds realizados no Google. E a escala dos builds do Google é realmente enorme: o Google executa milhões de builds, milhões de casos de teste e produz petabytes de saídas de build de bilhões de linhas de código-fonte todos os dias. Além de permitir que nossos engenheiros criem bases de código complexas rapidamente, esse sistema também nos permite implementar um grande número de ferramentas e sistemas automatizados que dependem do nosso build.