Bazel 的并行评估和增量模型。
数据模型
数据模型包含以下项:
SkyValue。也称为节点。SkyValues是不可变的对象,其中 包含在构建过程中构建的所有数据以及构建的输入。例如:输入文件、输出文件、目标和已配置的 目标。SkyKey。用于引用SkyValue的简短不可变名称,例如FILECONTENTS:/tmp/foo或PACKAGE://foo。SkyFunction。根据节点的键和依赖节点构建节点。- 节点图。一种数据结构,包含节点之间的依赖关系 。
Skyframe。Bazel 所基于的增量评估框架的代码名称。
评估
通过评估表示构建请求的节点来完成构建。
首先,Bazel 会找到与顶级
SkyKey的键对应的 SkyFunction。然后,该函数会请求评估它需要评估顶级节点的节点,这反过来会导致其他 SkyFunction 调用,直到到达叶节点。叶节点通常表示
文件系统中的输入文件。最后,Bazel 会得到
顶级 SkyValue 的值、一些副作用(例如文件
系统中的输出文件)以及构建中涉及的节点
之间的依赖关系的有向无环图。
如果 SkyFunction 无法提前知道完成其工作所需的所有节点,则可以分多次请求 SkyKeys。一个简单的示例是评估
一个输入文件节点,该节点最终是一个符号链接:该函数尝试读取
该文件,意识到它是一个符号链接,因此会提取表示符号链接目标的的文件系统节点
。但该节点本身也可以是一个符号链接,在
这种情况下,原始函数也需要提取其目标。
这些函数在代码中由接口 SkyFunction 表示,而
接口 SkyFunction.Environment 则向其提供服务。这些
是函数可以执行的操作:
- 通过调用
env.getValue请求评估另一个节点。如果 该节点可用,则返回其值;否则,返回null, 并且该函数本身应返回null。在后一种情况下, 系统会评估依赖节点,然后再次调用原始节点构建器,但这次相同的env.getValue调用将返回非null值。 - 通过调用
env.getValues(). 请求评估多个其他节点。这基本上是相同的,只不过依赖节点是 并行评估的。 - 在调用期间进行计算
- 产生副作用,例如将文件写入文件系统。需要注意避免两个不同的函数相互干扰。一般来说,写入副作用(数据从 Bazel 向外流动) 是可以的,读取副作用(数据在没有 注册依赖项的情况下流入 Bazel)是不可以的,因为它们是未注册的依赖项 ,因此可能会导致增量构建不正确。
行为良好的 SkyFunction 实现会避免以任何其他方式访问数据
而不是请求依赖项(例如直接读取文件系统),
因为这会导致 Bazel 不会注册对所读取文件的依赖项,
从而导致增量构建不正确。
一旦函数有足够的数据来完成其工作,就应返回一个非null
值,以表明已完成。
这种评估策略具有许多优势:
- 密封性。如果函数仅通过依赖于 其他节点来请求输入数据,则 Bazel 可以保证,如果输入状态相同,则 返回的数据也相同。如果所有 Sky 函数都是确定性的,这意味着 整个构建也将是确定性的。
- 正确且完美的增量。如果记录了所有函数的所有输入数据 ,则当输入数据发生变化时,Bazel 只能使需要 失效的确切节点集失效。
- 并行性。由于函数只能通过 请求依赖项来相互交互,因此不相互依赖的函数可以 并行运行,并且 Bazel 可以保证结果与按顺序运行的结果相同。
增量
由于函数只能通过依赖于其他节点来访问输入数据,因此 Bazel 可以构建从输入文件到输出 文件的完整数据流图,并使用此信息仅重建实际需要 重建的节点:更改的输入文件集的反向传递闭包。
具体来说,存在两种可能的增量策略:自下而上的策略 和自上而下的策略。哪种策略最佳取决于依赖关系图 的外观。
在自下而上的失效期间,在构建图并知道更改的 输入集后,所有传递依赖于 更改文件的节点都会失效。如果将再次构建相同的顶级节点,这是最佳选择 。请注意,自下而上的失效需要对先前构建的所有 输入文件运行
stat(),以确定它们是否已更改。可以使用inotify或类似机制来了解更改的文件,从而改进这一点。在自上而下的失效期间,系统会检查顶级节点的传递闭包 ,并且仅保留传递闭包干净的节点。 如果节点图很大,但下一个构建只需要其中的一小部分,则此方法更好:自下而上的失效会使第一个构建的较大图失效,而自上而下的失效只会遍历第二个构建的小图。
Bazel 仅执行自下而上的失效。
为了获得进一步的增量,Bazel 使用了 更改剪枝:如果某个节点 失效,但在重建时发现其新值与其旧值相同 ,则由于此节点中的更改而失效的节点 将 "复活"。
例如,如果您更改了 C++ 文件中的注释,则由此生成的
.o 文件将相同,因此无需再次调用
链接器。
增量链接 / 编译
此模型的主要限制是,节点的失效是一个 全有或全无的问题:当依赖项发生变化时,依赖节点始终是 从头开始重建的,即使存在更好的算法可以根据更改来更改 节点的旧值也是如此。以下是一些有用的示例:
- 增量链接
- 当 JAR 文件中的单个类文件发生变化时,可以 就地修改 JAR 文件,而不是再次从头开始构建。
Bazel 没有以原则性的方式支持这些功能的原因有两方面:
- 性能提升有限。
- 难以验证突变的结果是否与干净重建的结果相同,并且 Google 非常重视逐位可重复的构建。
到目前为止,通过分解开销高昂的 构建步骤并以这种方式实现部分重新评估,可以获得足够好的性能。例如, 在 Android 应用中,您可以将所有类拆分为多个组,并分别对它们进行 dex 处理。这样,如果组中的类未更改,则无需重新进行 dex 处理。
映射到 Bazel 概念
以下是 Bazel 用于执行构建的关键 SkyFunction 和 SkyValue
实现的简要总结:
- FileStateValue。
lstat()的结果。对于现有文件,该 函数还会计算其他信息,以便检测对 文件的更改。这是 Skyframe 图中的最低级别节点,没有 依赖项。 - FileValue 。供任何关心文件的实际内容或
解析路径的内容使用。依赖于相应的
FileStateValue和 需要解析的任何符号链接(例如,a/b的FileValue需要a的解析路径和a/b的解析路径)。FileValue和FileStateValue之间的区别非常重要,因为 后者可用于实际上不需要文件内容的情况。例如,在评估文件系统 glob(例如srcs=glob(["*/*.java"]))时,文件内容无关紧要。 - DirectoryListingStateValue。
readdir()的结果。与FileStateValue一样,这是最低级别的节点,没有依赖项。 - DirectoryListingValue。供任何关心目录条目的内容使用。依赖于相应的
DirectoryListingStateValue以及目录的关联FileValue。 - PackageValue 。表示 BUILD 文件的解析版本。依赖于
关联
BUILD文件的FileValue,并且还传递依赖于用于解析软件包中 glob 的任何DirectoryListingValue(在内部表示BUILD文件内容的数据结构)。 - ConfiguredTargetValue。表示已配置的目标,它是分析目标期间生成的一组操作的元组
,以及提供给依赖的已配置目标的信息。依赖于相应目标所在的
PackageValue、直接依赖项的ConfiguredTargetValues以及表示构建 配置的特殊节点。 - ArtifactValue。表示构建中的文件,无论是源工件还是
输出工件。工件几乎等同于文件,用于
在实际执行构建步骤期间引用文件。源文件
依赖于关联节点的
FileValue,而输出工件 依赖于生成工件的 任何操作的ActionExecutionValue。 - ActionExecutionValue。表示操作的执行。依赖于其输入文件的
ArtifactValues。它执行的操作包含在其 SkyKey 中,这与 SkyKeys 应较小的概念相反。请注意,如果 执行阶段未运行,则不会使用ActionExecutionValue和ArtifactValue。
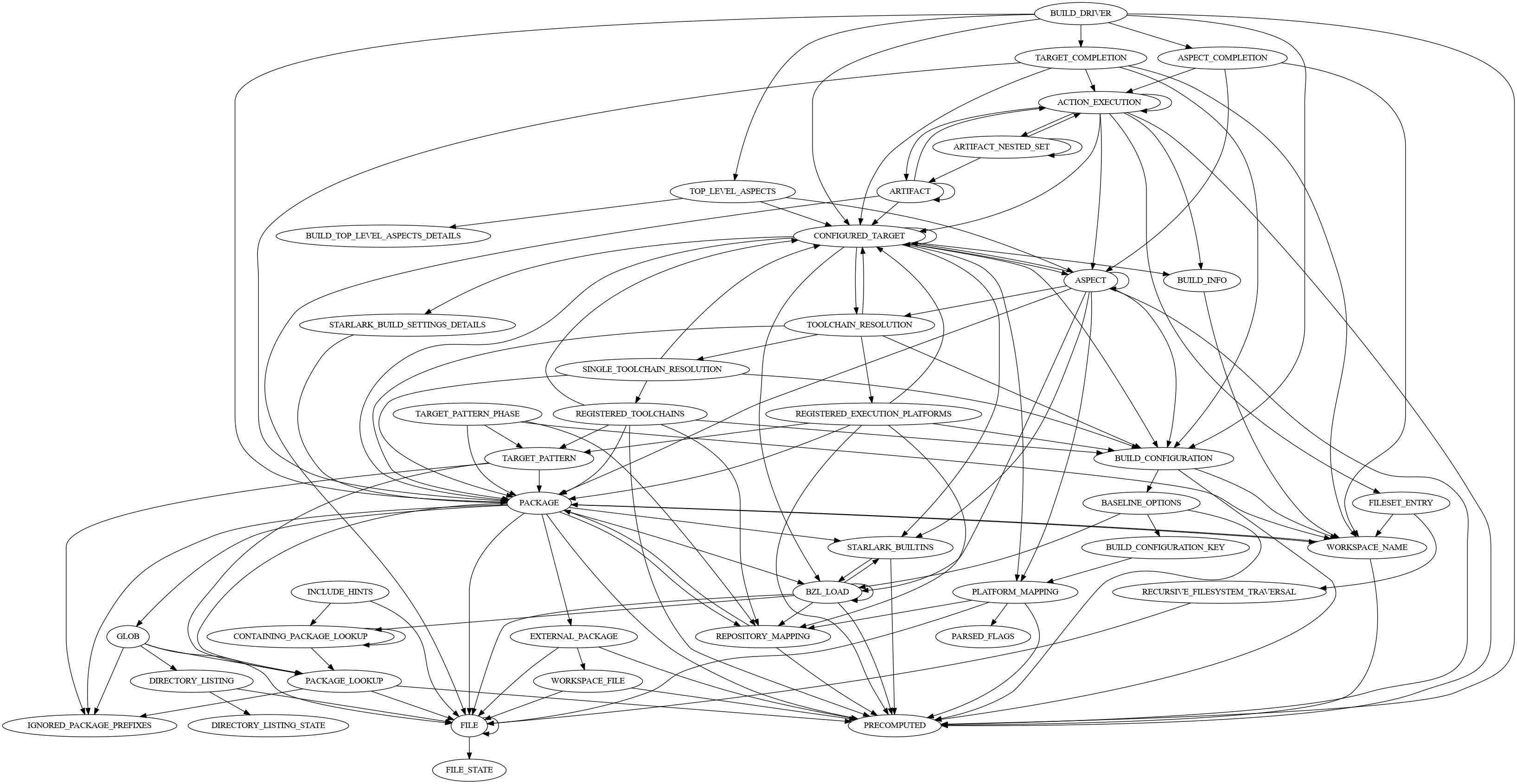
为了便于理解,下图显示了 Bazel 本身构建后 SkyFunction 实现之间的关系: