
コードベースが大きい場合、依存関係のチェーンが非常に深くなることがあります。単純なバイナリでも、数万個のビルド ターゲットに依存することがよくあります。この規模では、単一のマシンで妥当な時間内にビルドを完了することは不可能です。マシンのハードウェアに課せられた物理法則を回避できるビルドシステムはありません。これを実現する唯一の方法は、システムによって実行される作業単位が任意の数のスケーラブルなマシンに分散される分散ビルドをサポートするビルドシステムを使用することです。システムの作業を十分に小さな単位に分割していると仮定すると(これについては後で詳しく説明します)、任意のサイズのビルドを、支払う意思のある限り迅速に完了できます。このスケーラビリティは、アーティファクト ベースのビルドシステムを定義することで実現を目指してきたものです。
リモート キャッシュ
最も単純な分散ビルドは、図 1 に示すように、リモート キャッシュ保存のみを活用するものです。
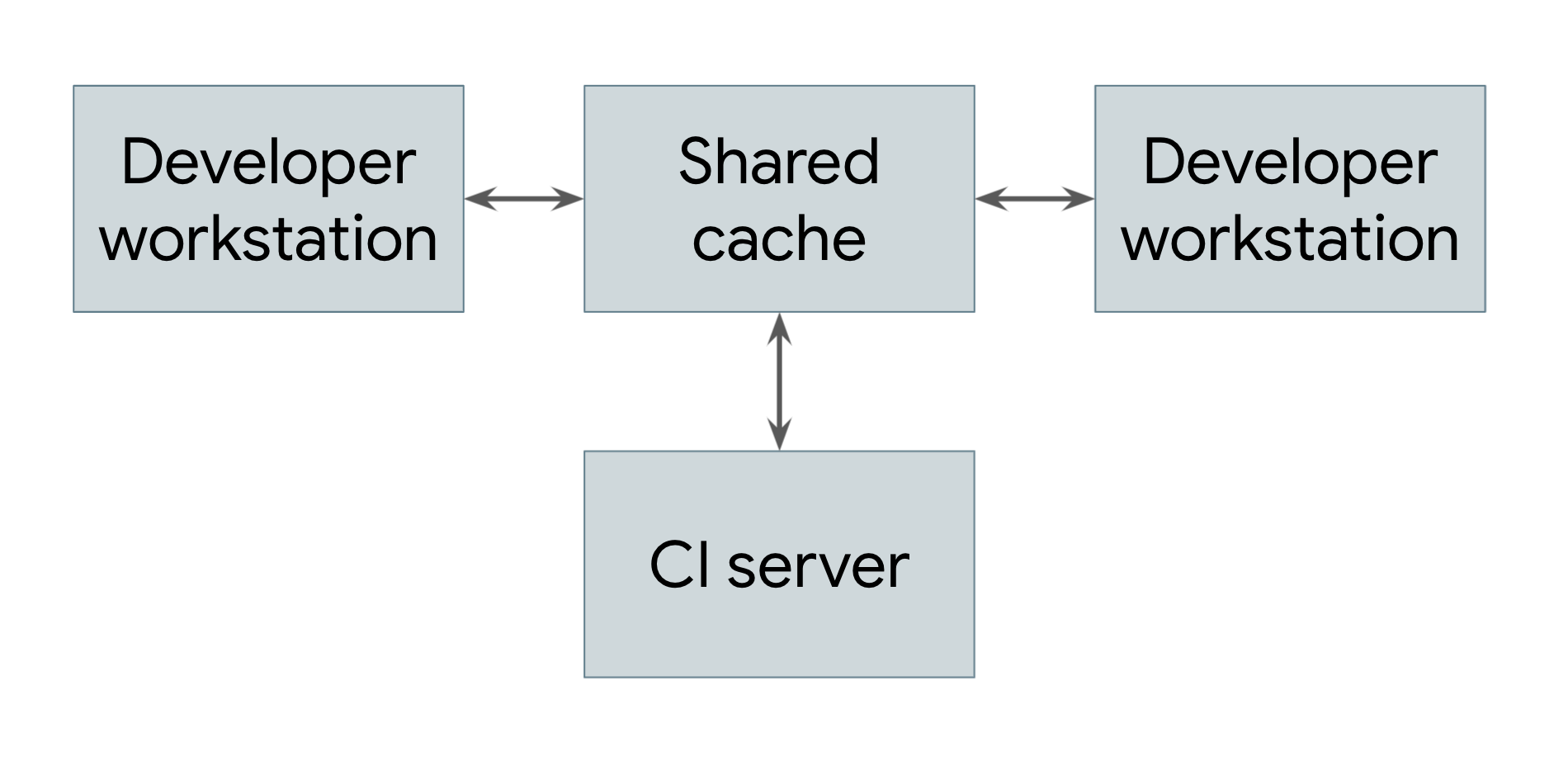
図 1. リモート キャッシュを示す分散ビルド
ビルドを実行するすべてのシステム(デベロッパー ワークステーションと継続的インテグレーション システムの両方を含む)は、共通のリモート キャッシュ サービスへの参照を共有します。このサービスは、Redis などの高速でローカルな短期ストレージ システムや、Google Cloud Storage などのクラウド サービスである可能性があります。ユーザーがアーティファクトを直接または依存関係としてビルドする必要がある場合、システムはまずリモート キャッシュをチェックして、そのアーティファクトがすでに存在するかどうかを確認します。その場合は、ビルドする代わりにアーティファクトをダウンロードできます。そうでない場合、システムはアーティファクトを自分でビルドし、結果をキャッシュにアップロードします。つまり、あまり変更されない低レベルの依存関係は、各ユーザーが再構築する必要はなく、一度構築してユーザー間で共有できます。Google では、多くのアーティファクトがゼロから構築されるのではなく、キャッシュから提供されるため、ビルドシステムの実行コストが大幅に削減されます。
リモート キャッシュ システムが機能するためには、ビルドシステムでビルドが完全に再現可能であることが保証されている必要があります。つまり、任意のビルド ターゲットについて、そのターゲットへの入力セットを決定できる必要があります。同じ入力セットを使用すると、どのマシンでもまったく同じ出力が生成されます。これは、アーティファクトのダウンロード結果が自分でビルドした結果と同じになるようにするための唯一の方法です。これには、キャッシュ内の各アーティファクトが、そのターゲットと入力のハッシュの両方でキー設定されている必要があります。これにより、異なるエンジニアが同じターゲットに同時に異なる変更を加えても、リモート キャッシュは結果として得られたすべてのアーティファクトを保存し、競合することなく適切に提供できます。
もちろん、リモート キャッシュのメリットを得るには、アーティファクトのダウンロードがビルドよりも高速である必要があります。特に、キャッシュ サーバーがビルドを行うマシンから遠く離れている場合は、必ずしもそうとは限りません。Google のネットワークとビルドシステムは、ビルド結果を迅速に共有できるように慎重に調整されています。
リモート実行
リモート キャッシュは真の分散ビルドではありません。キャッシュが失われた場合や、すべてを再ビルドする必要がある低レベルの変更を行った場合でも、マシンでビルド全体をローカルで実行する必要があります。真の目標は、ビルドの実際の作業を任意の数のワーカーに分散できるリモート実行をサポートすることです。図 2 は、リモート実行システムを示しています。
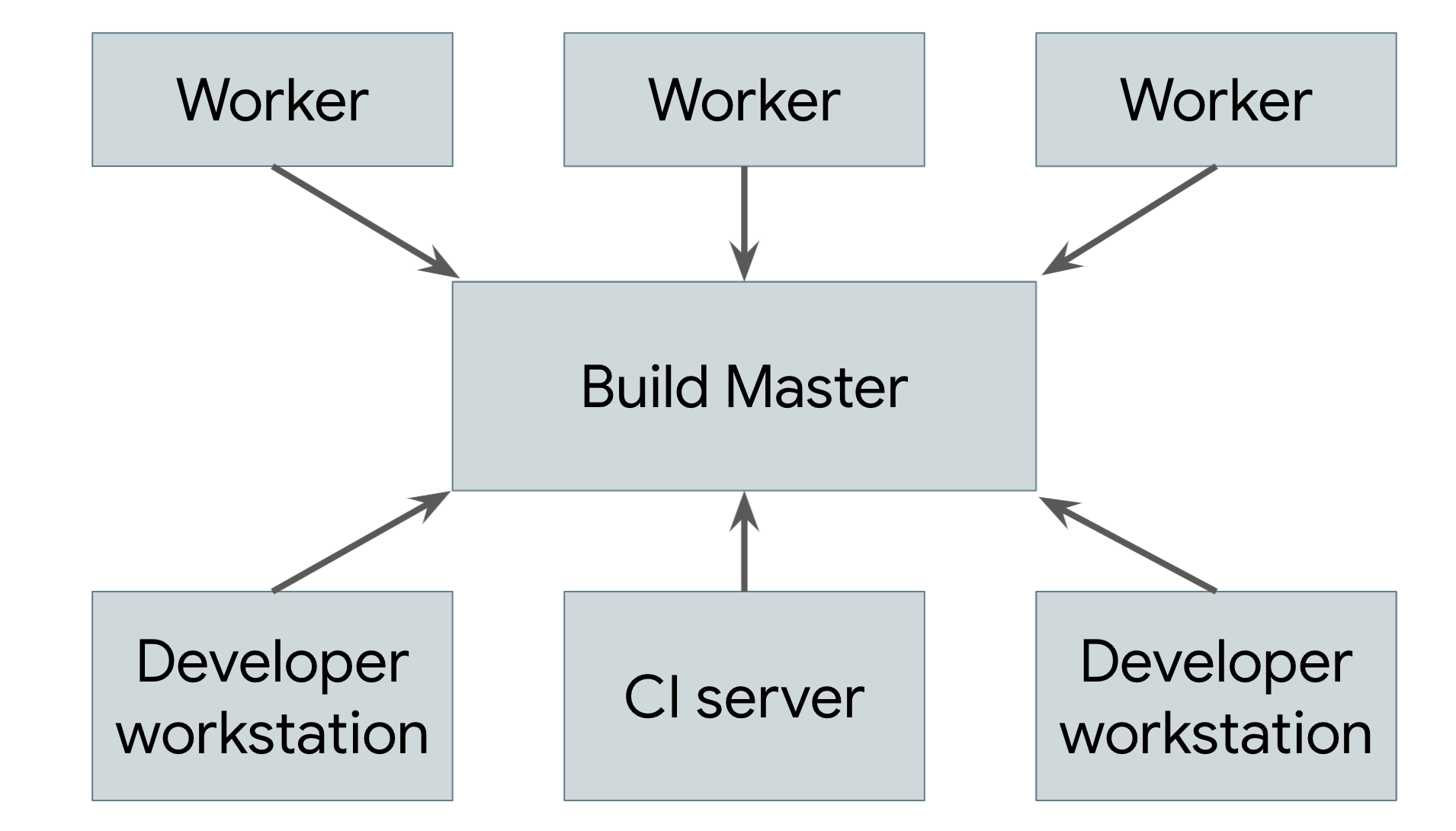
図 2. リモート実行システム
各ユーザーのマシンで実行されているビルドツール(ユーザーは人間のエンジニアまたは自動ビルドシステム)が、中央のビルドマスターにリクエストを送信します。ビルドマスターはリクエストをコンポーネント アクションに分割し、スケーラブルなワーカー プールでこれらのアクションの実行をスケジュールします。各ワーカーは、ユーザーが指定した入力を使用して、要求されたアクションを実行し、結果のアーティファクトを書き出します。これらのアーティファクトは、最終的な出力が生成されてユーザーに送信されるまで、それらを必要とするアクションを実行する他のマシン間で共有されます。
このようなシステムを実装するうえで最も難しいのは、ワーカー、マスター、ユーザーのローカル マシン間の通信を管理することです。ワーカーは他のワーカーが生成した中間アーティファクトに依存する可能性があり、最終的な出力はユーザーのローカルマシンに送り返す必要があります。これを行うには、各ワーカーが結果をキャッシュに書き込み、依存関係をキャッシュから読み取るようにして、前に説明した分散キャッシュを基盤として構築します。マスターは、依存するすべての処理が完了するまでワーカーの処理をブロックします。この場合、ワーカーはキャッシュから入力を読み取ることができます。最終的なプロダクトもキャッシュに保存されるため、ローカルマシンでダウンロードできます。また、ワーカーがビルド前に変更を適用できるように、ユーザーのソースツリー内のローカル変更をエクスポートする別の手段も必要です。
これを行うには、前述のアーティファクト ベースのビルドシステムのすべての部分を統合する必要があります。ビルド環境は完全に自己記述型でなければなりません。これにより、人手を介さずにワーカーをスピンアップできます。各ステップは異なるマシンで実行される可能性があるため、ビルドプロセス自体が完全に自己完結型である必要があります。出力は完全に決定論的である必要があります。これにより、各ワーカーは他のワーカーから受け取った結果を信頼できます。このような保証をタスクベースのシステムで提供することは非常に難しく、その上に信頼性の高いリモート実行システムを構築することはほぼ不可能です。
Google での分散ビルド
2008 年以降、Google はリモート キャッシュ保存とリモート実行の両方を使用する分散ビルドシステムを使用しています(図 3 を参照)。
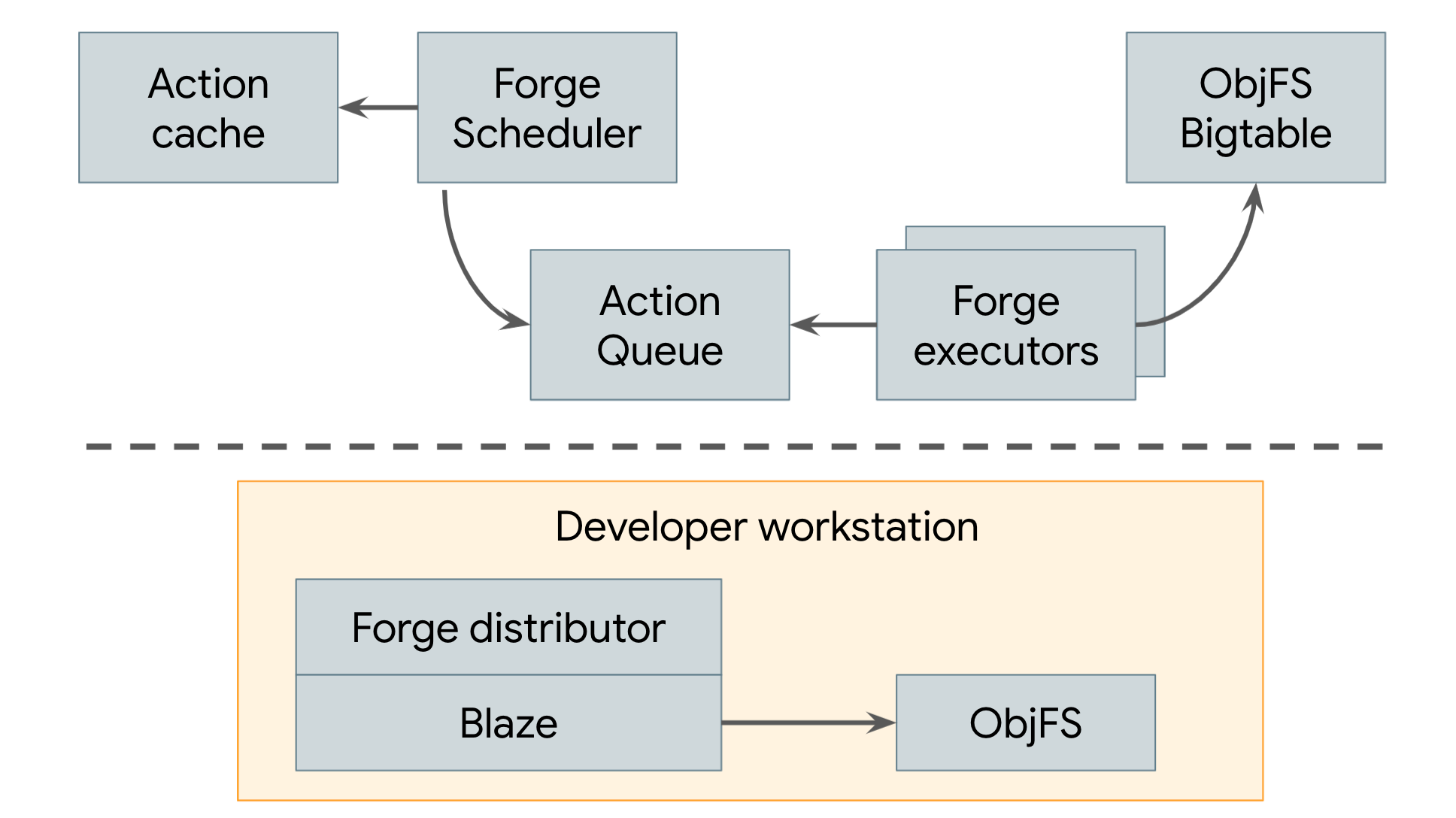
図 3. Google の分散ビルドシステム
Google のリモート キャッシュは ObjFS と呼ばれます。これは、Google の本番環境マシンのフリート全体に分散された Bigtable にビルド出力を保存するバックエンドと、各デベロッパーのマシンで実行される objfsd という名前のフロントエンド FUSE デーモンで構成されています。FUSE デーモンを使用すると、エンジニアはビルド出力をワークステーションに保存された通常のファイルのように参照できますが、ファイル コンテンツはユーザーが直接リクエストした少数のファイルに対してのみオンデマンドでダウンロードされます。ファイル コンテンツをオンデマンドで提供することで、ネットワークとディスクの使用量が大幅に削減され、すべてのビルド出力をデベロッパーのローカル ディスクに保存した場合と比較して、システムのビルド速度が 2 倍になりました。
Google のリモート実行システムは Forge と呼ばれます。Blaze(Bazel の内部同等物)の Forge クライアントである Distributor は、各アクションのリクエストを、Scheduler と呼ばれるデータセンターで実行されているジョブに送信します。スケジューラはアクション結果のキャッシュを保持しているため、システム内の他のユーザーによってアクションがすでに作成されている場合は、すぐにレスポンスを返すことができます。そうでない場合は、アクションをキューに入れます。Executor ジョブの大きなプールが、このキューからアクションを継続的に読み取り、実行して、結果を ObjFS Bigtable に直接保存します。これらの結果は、今後のアクションのために実行者に提供されるか、objfsd を介してエンドユーザーがダウンロードできます。
最終的には、Google で実行されるすべてのビルドを効率的にサポートするシステムが完成します。Google のビルドの規模は非常に大きく、毎日数百万件のビルドを実行し、数百万件のテストケースを実行し、数十億行のソースコードからペタバイト単位のビルド出力を生成しています。このようなシステムにより、エンジニアは複雑なコードベースを迅速に構築できるだけでなく、ビルドに依存する多数の自動化ツールやシステムを実装することもできます。