
Cuando tienes una base de código grande, las cadenas de dependencias pueden volverse muy profundas. Incluso los objetos binarios simples suelen depender de decenas de miles de destinos de compilación. A esta escala, es imposible completar una compilación en un tiempo razonable en una sola máquina: ningún sistema de compilación puede eludir las leyes fundamentales de la física impuestas en el hardware de una máquina. La única forma de lograr esto es con un sistema de compilación que admita compilaciones distribuidas, en el que las unidades de trabajo que realiza el sistema se distribuyen en una cantidad arbitraria y escalable de máquinas. Si suponemos que dividimos el trabajo del sistema en unidades lo suficientemente pequeñas (más sobre esto más adelante), esto nos permitiría completar cualquier compilación de cualquier tamaño tan rápido como estemos dispuestos a pagar. Esta escalabilidad es el santo grial que buscamos al definir un sistema de compilación basado en artefactos.
Almacenamiento en caché remota
El tipo más simple de compilación distribuida es aquel que solo aprovecha el almacenamiento en caché remoto, como se muestra en la Figura 1.
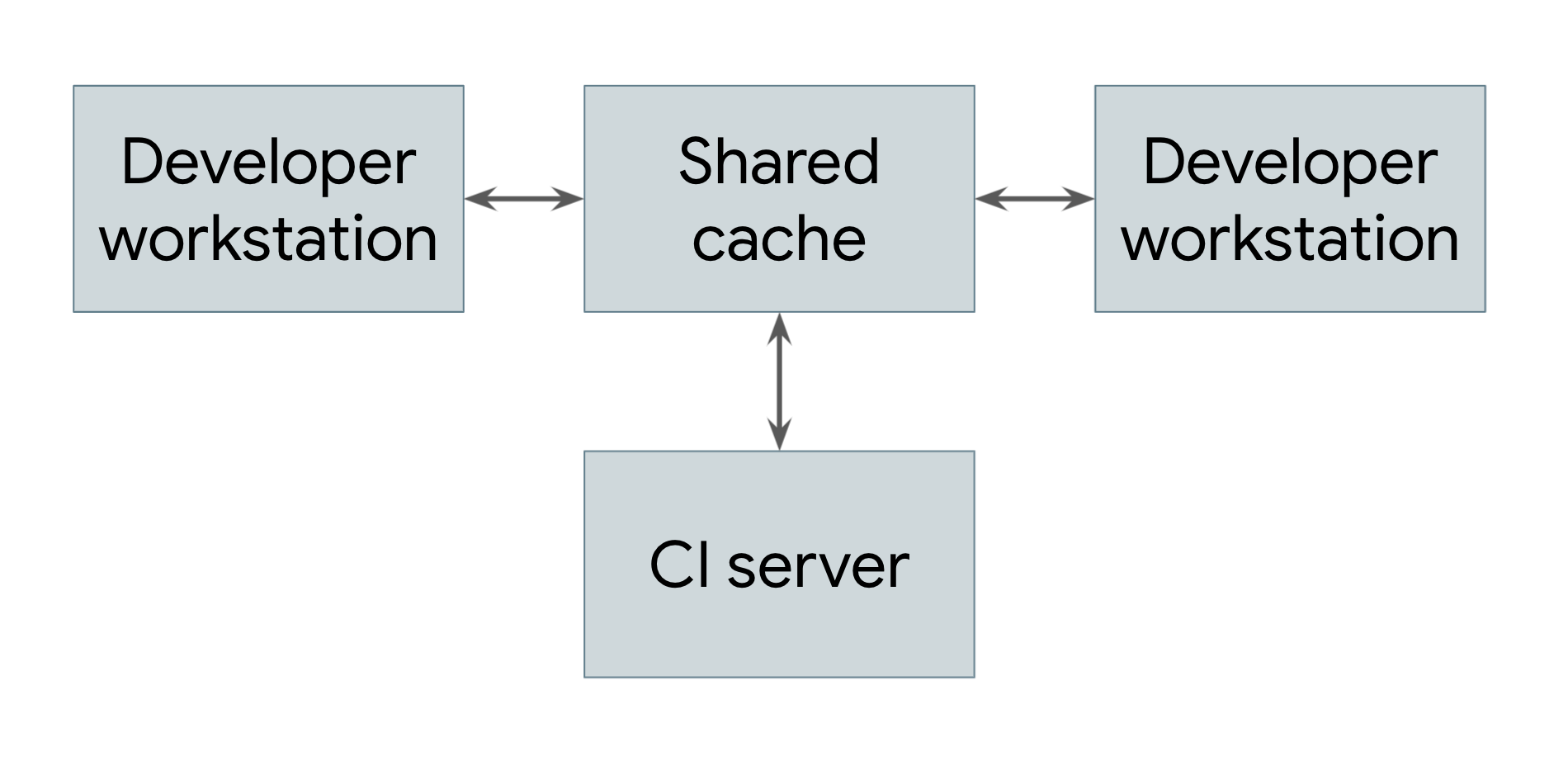
Figura 1. Una compilación distribuida que muestra el almacenamiento en caché remoto
Todos los sistemas que realizan compilaciones, incluidas las estaciones de trabajo de los desarrolladores y los sistemas de integración continua, comparten una referencia a un servicio de caché remoto común. Este servicio puede ser un sistema de almacenamiento local y rápido a corto plazo, como Redis, o un servicio en la nube, como Google Cloud Storage. Cada vez que un usuario necesita compilar un artefacto, ya sea directamente o como dependencia, el sistema primero verifica la caché remota para ver si el artefacto ya existe allí. Si es así, puede descargar el artefacto en lugar de compilarlo. De lo contrario, el sistema compila el artefacto y sube el resultado a la caché. Esto significa que las dependencias de bajo nivel que no cambian con mucha frecuencia se pueden compilar una vez y compartir entre los usuarios en lugar de que cada usuario las tenga que volver a compilar. En Google, muchos artefactos se entregan desde una caché en lugar de compilarse desde cero, lo que reduce en gran medida el costo de ejecutar nuestro sistema de compilación.
Para que un sistema de almacenamiento en caché remoto funcione, el sistema de compilación debe garantizar que las compilaciones sean completamente reproducibles. Es decir, para cualquier destino de compilación, debe ser posible determinar el conjunto de entradas para ese destino de modo que el mismo conjunto de entradas produzca exactamente la misma salida en cualquier máquina. Esta es la única forma de garantizar que los resultados de descargar un artefacto sean los mismos que los de compilarlo por cuenta propia. Ten en cuenta que esto requiere que cada artefacto de la caché se indexe tanto en su destino como en un hash de sus entradas. De esa manera, diferentes ingenieros podrían realizar diferentes modificaciones en el mismo destino al mismo tiempo, y la caché remota almacenaría todos los artefactos resultantes y los publicaría de manera adecuada sin conflictos.
Por supuesto, para que la caché remota sea beneficiosa, la descarga de un artefacto debe ser más rápida que su compilación. Esto no siempre es así, en especial si el servidor de caché está lejos de la máquina que realiza la compilación. La red y el sistema de compilación de Google se ajustan cuidadosamente para poder compartir rápidamente los resultados de la compilación.
Ejecución remota
El almacenamiento en caché remoto no es una compilación distribuida real. Si se pierde la caché o si realizas un cambio de bajo nivel que requiere que se vuelva a compilar todo, deberás realizar toda la compilación de forma local en tu máquina. El objetivo real es admitir la ejecución remota, en la que el trabajo real de la compilación se puede distribuir entre cualquier cantidad de trabajadores. En la figura 2, se muestra un sistema de ejecución remota.
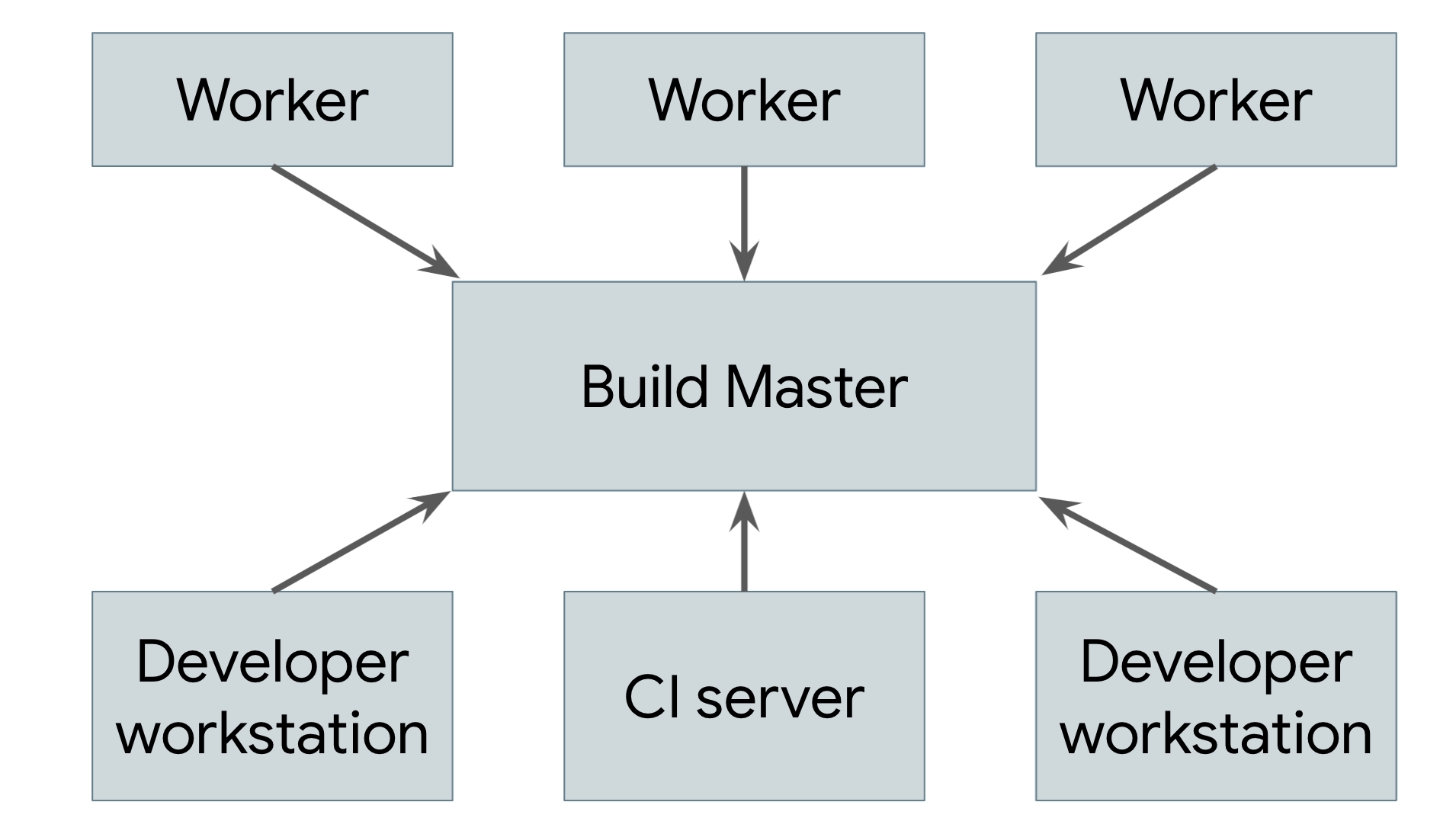
Figura 2. Un sistema de ejecución remota
La herramienta de compilación que se ejecuta en la máquina de cada usuario (en la que los usuarios son ingenieros humanos o sistemas de compilación automatizados) envía solicitudes a un compilador central principal. El compilador principal divide las solicitudes en sus acciones componentes y programa la ejecución de esas acciones en un grupo escalable de trabajadores. Cada trabajador realiza las acciones que se le solicitan con las entradas especificadas por el usuario y escribe los artefactos resultantes. Estos artefactos se comparten entre las otras máquinas que ejecutan acciones que los requieren hasta que se puede producir el resultado final y enviarlo al usuario.
La parte más difícil de implementar un sistema de este tipo es administrar la comunicación entre los trabajadores, el maestro y la máquina local del usuario. Los trabajadores pueden depender de artefactos intermedios producidos por otros trabajadores, y el resultado final debe enviarse de vuelta a la máquina local del usuario. Para ello, podemos aprovechar la caché distribuida que se describió anteriormente haciendo que cada trabajador escriba sus resultados en la caché y lea sus dependencias de ella. El proceso principal impide que los trabajadores continúen hasta que finalice todo lo que necesitan, en cuyo caso podrán leer sus entradas desde la caché. El producto final también se almacena en caché, lo que permite que la máquina local lo descargue. Ten en cuenta que también necesitamos un medio independiente para exportar los cambios locales en el árbol de origen del usuario, de modo que los trabajadores puedan aplicar esos cambios antes de la compilación.
Para que esto funcione, todas las partes de los sistemas de compilación basados en artefactos que se describieron anteriormente deben unirse. Los entornos de compilación deben ser completamente autodescriptivos para que podamos iniciar trabajadores sin intervención humana. Los procesos de compilación deben ser completamente autónomos, ya que cada paso podría ejecutarse en una máquina diferente. Los resultados deben ser completamente determinísticos para que cada trabajador pueda confiar en los resultados que recibe de otros trabajadores. Esas garantías son extremadamente difíciles de proporcionar para un sistema basado en tareas, lo que hace casi imposible crear un sistema de ejecución remota confiable sobre uno de ellos.
Compilaciones distribuidas en Google
Desde 2008, Google utiliza un sistema de compilación distribuido que emplea tanto el almacenamiento en caché remoto como la ejecución remota, como se ilustra en la Figura 3.
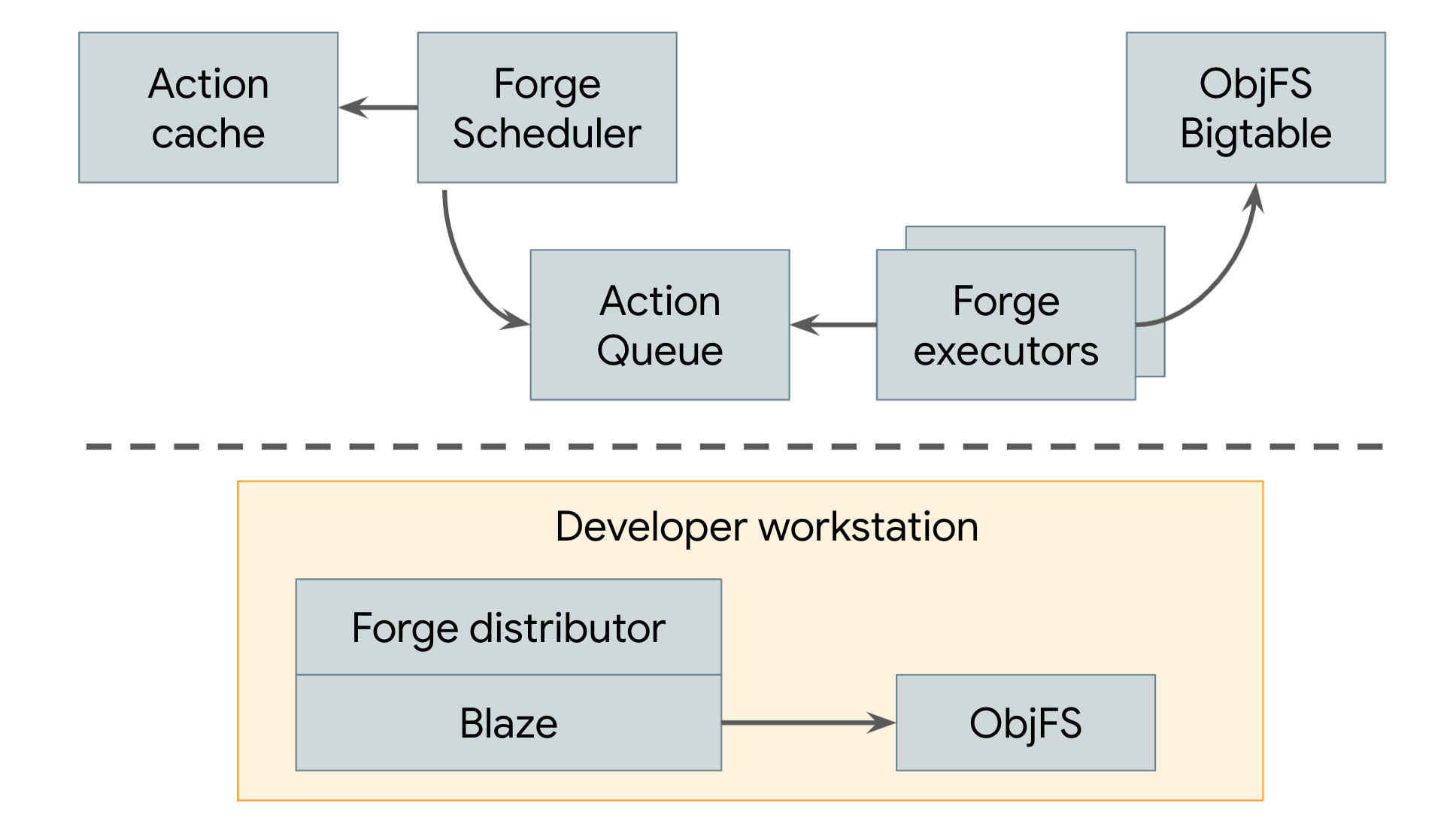
Figura 3. Sistema de compilación distribuido de Google
La caché remota de Google se llama ObjFS. Consta de un backend que almacena los resultados de la compilación en tablas de Bigtable distribuidas en toda nuestra flota de máquinas de producción y un daemon de FUSE de frontend llamado objfsd que se ejecuta en la máquina de cada desarrollador. El daemon de FUSE permite a los ingenieros explorar los resultados de la compilación como si fueran archivos normales almacenados en la estación de trabajo, pero con el contenido del archivo descargado a pedido solo para los pocos archivos que solicita directamente el usuario. Publicar el contenido de los archivos a pedido reduce en gran medida el uso de la red y el disco, y el sistema puede compilar el doble de rápido en comparación con cuando almacenábamos todos los resultados de la compilación en el disco local del desarrollador.
El sistema de ejecución remota de Google se llama Forge. Un cliente de Forge en Blaze (el equivalente interno de Bazel) llamado Distributor envía solicitudes para cada acción a un trabajo que se ejecuta en nuestros centros de datos llamado Scheduler. El programador mantiene una caché de los resultados de las acciones, lo que le permite devolver una respuesta de inmediato si otro usuario del sistema ya creó la acción. De lo contrario, la coloca en una fila. Un gran grupo de trabajos de Executor lee continuamente las acciones de esta cola, las ejecuta y almacena los resultados directamente en las tablas de Bigtable de ObjFS. Los ejecutores pueden usar estos resultados para acciones futuras, o el usuario final puede descargarlos a través de objfsd.
El resultado final es un sistema que se adapta para admitir de manera eficiente todas las compilaciones que se realizan en Google. Y la escala de las compilaciones de Google es realmente masiva: Google ejecuta millones de compilaciones que ejecutan millones de casos de prueba y producen petabytes de resultados de compilación a partir de miles de millones de líneas de código fuente todos los días. Este sistema no solo permite que nuestros ingenieros creen bases de código complejas rápidamente, sino que también nos permite implementar una gran cantidad de herramientas y sistemas automatizados que dependen de nuestra compilación.